
硅光计算芯片后摩尔时代人工智能算力基座
计算研究始于20世纪60年代,但受到当时应用场景范围有限以及电子计算技术加快速度进行发展的影响,光计算处理器未能成功迈向商用。时过境迁,人工智能(AI)快速的提升,以ChatGPT为代表的大语言模型所展现的强大能力引发全球关注,紫东太初、悟道、混元、文心、通义、盘古、言犀等一大批千亿级乃至万亿级参数的国产大模型不断涌现,大有引发新一轮科技与产业变革之势。高性能大模型拥有庞大参数规模、要求海量数据高效处理和高速传输,即使是当前最先进的电子计算平台也慢慢的出现计算、存储和传输的瓶颈。大模型的创新发展和迭代,离不开海量数据及高质量数据集的构建,更要依靠大算力集群来支撑训练和推理。近期,大模型训练计算量平均每2个月就要翻倍,激增的算力需求已远超摩尔定律。因此,光子计算近年来又重新受到广泛关注。
当前,大模型训练和推理的硬件以通用图形处理单元(GPU)为主,2022年全球GPU市场规模达到448.3亿美元,美国AI芯片巨头英伟达公司占有80%的市场占有率并仍在持续攀升。目前,中国仍以英伟达的产品作为主流算力平台,只有较小规模的算力来自国产神经网络加速平台。然而,自2021年起,美国对中国集成电路领域实行了最为严苛的技术封锁,限制向我国出口最先进的AI芯片和软件。英伟达向我国提供的AI芯片是传输带宽受限的特别版本,使用该版本GPU组成的超算集群的训练和推理效率均落后于国外同期产品。因此,算力基建亟需向自主可控的国产化迈进。
,其主要使用专用集成电路(ASIC)硬件架构,用于特定算法或应用场景的优化,
算的AI芯片的国产化之路受技术封锁影响仍需突破重重阻碍,尤其是受限于先进工艺制程,国产同类芯片在能耗、算力、带宽等方面难以在短期内赶超。
光子器件具有高速、大带宽和低功耗的特点,在信息传输和处理方面具备极其重大优势,而且光信号可以在光子器件中并行传输和处理。
这使得光子计算能更好地实现海量数据的高效处理,也能够尽可能的防止电子信号传输带来的噪声和时延等问题,更好地实现高带宽的传输互连,从而为大模型提供关键支撑。
此外,与最先进的电子神经网络架构及数字电子系统相比,光子计算架构在速度和能效上优势突出。
因此,光子计算可以有明显效果地突破传统电子器件的性能瓶颈,满足高速、低功耗通信和计算的需求。
需要指出的是,光子计算的发展目标不是要取代传统计算机,而是要辅助已有计算技术在基础物理研究、非线性规划、机器学习加速和智能信号处理等应用场景更高效地实现低延迟、大带宽和低能耗。
硅光计算芯片通过在单个芯片上集成多种光子器件实现了更高的集成度,还能兼容现有半导体制造工艺,降低成本。
光子计算芯片包括激光器、光波导、光调制器、光探测器等主要元件,运行过程大致如图1所示:
激光器产生的光,经过光波导传输到光调制器实现对光信号的控制和处理,最后传输到光探测器将光信号转换为电信号,再进行后续的处理和输出。
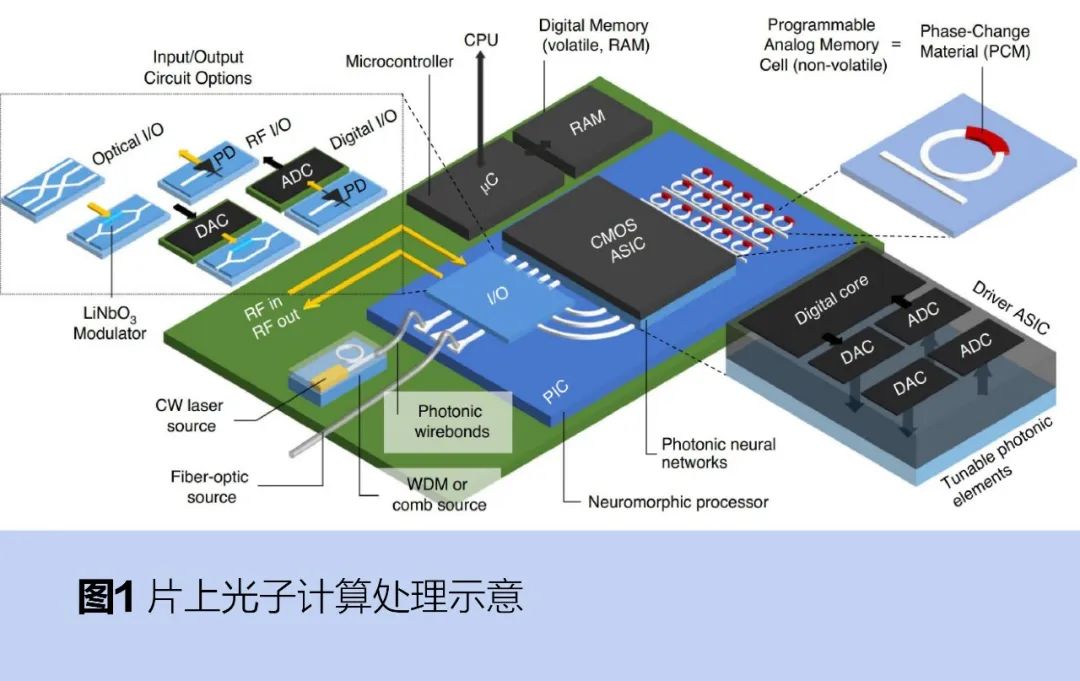
人工神经网络(ANN)是现有AI大模型的重要基础,由人工神经元相互连接组成,连接强弱由权重大小决定,权重即模型参数。利用光计算在信息传输、处理和并行计算等方面和光通信在片内、片间和板级系统间数据传输等方面的优势,硅光计算芯片可对神经网络训练和推理过程中的大规模矩阵运算、神经元非线性运算进行加速;还可通过对不同神经网络的拓扑结构可以进行硬件结构映射,来提高芯片的通用性和灵活性。
在人工神经网络计算加速方面,基于硅光平台的神经网络已取得多项进展。例如,2017年沈亦晨等人提出一种基于硅光平台的全光前馈神经网络架构,采用马赫-曾德干涉仪(MZI)进行神经元线性部分的计算,非线性激活函数则通过电域仿线年阿什蒂亚尼等人采用可调光衰减器实现权重调节。随技术的发展,基于硅光平台的神经网络也逐步走向商业化。例如,美国AI芯片公司Lightmatter推出通用光子AI加速器方案“Envise”;曦智科技于2021年发布光子计算处理器“PACE”。
人工神经网络是大脑神经元的极简数学模型,目前仍没办法实现推理归纳、联想想象、学习记忆等大脑的高级功能,而且现有AI大模型的功耗水平远高于人类大脑。受脑科学和神经科学研究的启发,学界提出了下一代AI基础——脉冲神经网络(SNN)。其利用与大脑神经元表现极为近似的脉冲神经元搭建整个网络结构,具备模拟生物大脑的网络结构和信息处理的潜能,通过部署到模拟计算硬件上,能发挥低延时、低功耗等特性,为类脑大模型的训练和推理提供了可能性。
目前,围绕基于硅光平台的脉冲神经网络,已有科研团队利用硅波导和相变材料集成等方式实现了光学突触、光子脉冲神经元乃至全光脉冲神经网络的构建。例如,2019年费尔德曼等人构建基于集成可塑突触的全光脉冲神经网络,将可塑突触上的相变材料晶化程度作为权重,将微环谐振器上的相变材料胞体相变阈值能量作为神经元阈值调控激活函数,实现有监督和无监督学习。
在片上和片间光互连、高速光通信、集成传感和智能计算等应用场景,光开关都是硅光集成所需的核心器件。当前,硅光集成开关器件主要是采用马赫-曾德干涉仪或微环谐振器的结构设计,这一些器件存在占用空间大、对外界温度敏感以及因需要持续外部电源维持开关状态导致的高静态功耗等问题,为高密度的硅光集成带来了额外的困难。
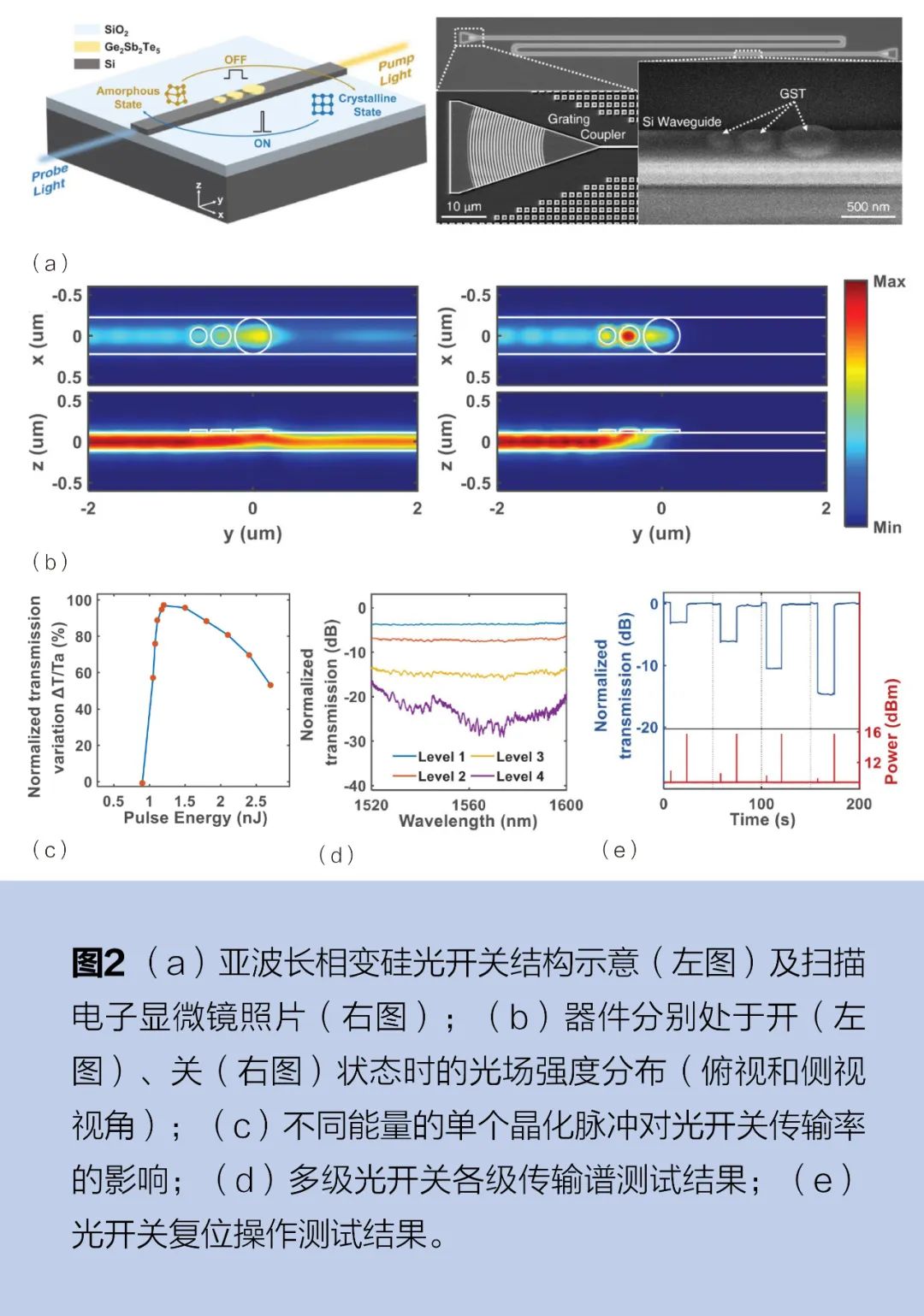
2022年,中国科学院上海微系统与信息系统研究所(以下简称上海微系统所)武爱民研究员团队研制出基于亚波长相变结构的超小尺寸、高消光比、低能耗和良好结构稳定性的片上光子开关。这一新的光开关器件结构,由单模硅光波导和3个级联的锗锑碲化合物Ge2Sb2Te5(以下简称GST)纳米盘组成,见图2a,总体积仅为0.229μm2×35nm。在通信波段,GST是一种具有高光学对比度的相变材料(PCM),非晶态下的折射率与硅相近,具有较低的消光系数,而晶态下的折射率则会增大两倍。通过改变GST纳米盘的相态可以调制沿波导传输的光强。GST处于非晶态时,波导中的光可以正常通过;而处于晶态时,沿波导输入的入射光被级联的GST纳米盘吸收或散射,实现对入射光的截止,见图2b。受益于GST的非易失性,光开关的开关状态是可持续的,在施加控制脉冲后不会产生额外的能量消耗。在实验中,通过对光开关施加不同能量的泵浦脉冲光,精确地加热GST纳米盘以切换其相位,以此来实现对相变材料的调控,图2c展示了波导中传输率的变化和脉冲能量的关系。实验测得,该器件在C波段实现了高达27dB的超高消光比,并能在70nm的宽带范围内保持20dB以上的高消光性能,见图2d;通过施加特定能量的光脉冲,可对非同级状态的光开关实现复位操作,见图2e。由于GST材料已具备在互补金属氧化物半导体(CMOS)平台上的加工能力,与单模波导制备的光开关结合能够直接应用于规模化集成的光子芯片中,该工作有望在大规模集成的光互连和光计算新型架构等方面发挥及其重要的作用。相关成果以《基于结构化相变材料的超紧凑高消光比非易失性片上开关》
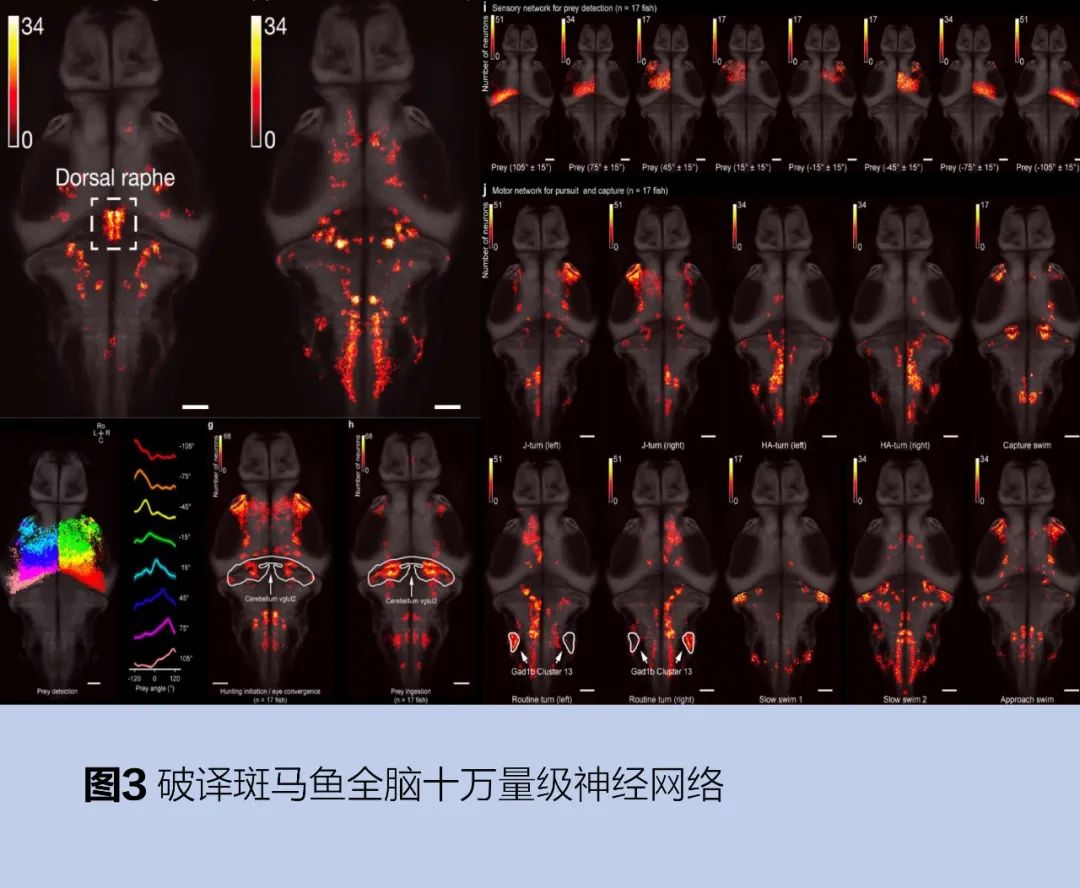
上海微系统所李孟研究员团队长期从事脑科学与AI的交叉领域研究,研究方向最重要的包含两个方面:一是应用AI技术解决脑科学领域的重要问题,如使用深度神经网络对脑科学研究中动物的复杂行为做多元化的分析和建模,并建立生物大脑神经网络活动信号与动物行为模式的对应关系,以理解生物复杂行为、内在状态是如何被大脑神经网络表达、计算和调控的;二是根据脑科学前沿发现,将脑科学领域的最新成果和原理应用于类脑算法研究,致力于研发更符合生物神经系统特性的类脑算法和相应硬件,建立面向应用的类脑系统框架。在大脑破译方向,尤其是大尺度群体神经信号编解码领域取得系列创新成果。2019年,解码了十万神经元量级的全脑神经信号,如图3所示,揭示了大脑内在状态动态转化的控制机理,建立了复杂高阶行为与大脑神经网络内在状态间的关系,相关成果以《内部状态动态塑造了全脑活动和觅食行为》
当前,两个团队正在合作研究基于硅光平台的受脑科学和神经科学启发的下一代AI计算芯片。目标是使其具有网络低功耗、低延时等性能优势,可执行因果推理、在线学习、终身学习、长时记忆、联想想象、行为决策等类脑复杂功能及高级智能行为,并能大范围的应用于智能人形机器人、无人驾驶、仿生传感器、智能安防与检测、脑机接口等前沿领域。
AI创新时代,算力即为生产力。《2022—2023全球计算力指数评估报告》显示,信息技术的支出每投入1美元,可以拉动29美元的国内生产总值(GDP)产出。随着AI和计算科学的发展,大模型训练和海量数据处理对于计算的需求将呈爆发式增长。
以光子计算技术为核心的硅光计算芯片,有望成为后摩尔时代AI算力基座。其主要优点是:一是高速计算能力,即光计算具有快速传输和解决能力,可实现神经网络中所需的高速计算;二是低功耗特性,即相比于传统的电子计算,光计算利用光信号进行信息传输和处理,可降低能耗;三是并行计算能力,即光信号可在光子器件中并行传输,在光学神经网络中可实现更高效的并行计算。
硅光计算芯片在AI和计算科学领域走向大范围的应用也面临一定挑战。例如,当前单个光子矩阵运算规模较小,不足以满足大模型所需的计算需求;硅光计算芯片的设计尚未最大限度地考虑集群化的应用情形,限制了芯片的可扩展能力;由于光信号是模拟信号,光子矩阵计算尚不支持浮点数运算,无法直接表示和处理浮点数据的精确值,而AI模型训练则需要浮点数运算作为支持。
对标全球AI芯片行业翘楚,将硅光计算芯片打造成为未来AI和计算科学领域的主流计算平台,需要构建完整、可持续的软硬件生态环境。例如,硅光计算芯片的底层设计需要引入可微分思想,使其具有可扩展性;通过软硬件协同,针对不同规模的硅光计算芯片和应用场景,开发硅光计算芯片的底层编译器、高级编程语言接口、硬件驱动,以及基于开源指令集(如RSIC-V等)的硅光芯片专用计算指令集;开发面向AI和计算科学的学习框架和计算加速库,更广泛地吸引各领域有关人员利用硅光计算芯片开展研发工作,建设硅光计算社群,助推硅光计算蒸蒸日上。通过构建硅光计算芯片的完整软硬件生态,硅光计算的核心竞争力将大幅度的提高,为未来AI芯片领域的国产化超越贡献力量。
本文刊登于IEEE Spectrum中文版《科技纵览》2023年11月刊。
*博客内容为网友个人发布,仅代表博主个人自己的观点,如有侵权请联系工作人员删除。